《Similarity-based Memory Enhanced Joint Entity and Relation Extraction》论文阅读笔记
代码
原文
摘要
文档级联合实体和关系抽取是一项难度很大的信息抽取任务,它要求用一个神经网络同时完成四个子任务,分别是:提及检测、共指消解、实体分类和关系抽取。目前的方法大多采用顺序的多任务学习方式,这种方式将任务任意分解,使得每个任务只依赖于前一个任务的结果,而忽略了任务之间可能存在的更复杂的相互影响。为了解决这些问题,本文提出了一种新的多任务学习框架,设计了一个统一的模型来处理所有的子任务,该模型的工作流程如下:首先,识别出文本中的实体提及,并将它们聚合成共指簇;其次,为每个实体簇分配一个合适的实体类型;最后,在实体簇之间建立关系。图 1 给出了一个来自 DocRED 数据集的文档示例,以及模型期望输出的实体簇图。为了克服基于流水线的方法的局限性,在模型中引入了双向的记忆式依赖机制,使得各个子任务能够相互影响和提升,从而更有效地完成联合任务。

模型架构

该方法受到了 JEREX 的启发,由四个任务特定的组件组成:提及抽取(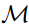

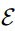



Memory reading
该方法与 TriMF 类似,都是利用注意力机制,将输入表示与从记忆中读取的信息相结合,得到扩展的表示。如图 2 所示,本文的架构对两种输入表示进行了扩展:一种是词嵌入 
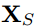

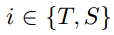

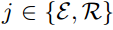
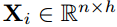

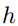
作为查询,注意力机制使用记忆矩阵 
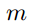
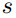
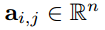
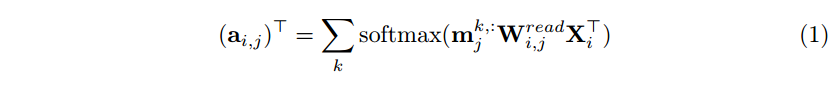
其中 







对于每一种输入表示
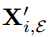


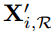
Memory writing

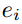


给定实体对 
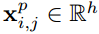

定义 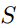



其中 

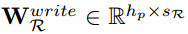


Training
最后,模型被训练优化关节损失



本文还纳入了TriMF中提出的两阶段训练方法,在超参数搜索过程中调整记忆预热比例。